Motivation
A common applied workflow is: collect data, train a model, then deploy it once it is accurate enough. In Bayesian inference, the model encodes your current state of knowledge (and therefore, uncertainty) given what you have observed so far. During data collection, optimal experiment design (OED) uses that current state to decide which experiment or observation to run next so that uncertainty shrinks quickly. Done well, this can reduce the amount of data you need to reach a useful level of performance, shorten the time needed to make a decision, and avoid spending resources (or opportunity cost) on uninformative measurements.
OED is useful when the pool of possible observations is much larger than what will ever be used for training (clinical trials, A/B testing, ad experiments, surveys). In those settings, spending some compute to choose data can be a good trade since collecting uninformative data is expensive.
In typical variants of optimal experiment design, this idea is formalized by scoring candidate designs by expected information gain. A common choice is mutual information (MI): the “best” experiment is the one expected to reduce uncertainty the most about whatever you care about (parameters, predictions, or another derived random variable).
Mutual information can be written as an expected reduction in entropy. For a proposed batch design $\mathcal{D}_{1:k}$ and outcomes $y_{1:k}$, the parameter-learning objective is:
Here $\theta$ denotes the current uncertain state of the model at the moment you score designs (e.g., a current posterior state). Intuitively: start from your current uncertainty, then subtract the expected uncertainty after running the batch and updating the model.
Predictive MI uses the same form, replacing $\theta$ with the predictive quantity of interest.
Modifications to the above are useful when the relevant notion of “uncertainty” isn’t purely Shannon entropy—for example, using similarity-sensitive entropy to encode which distinctions matter for your downstream goal. See Similarity-Sensitive Entropy under Representation Change and Inference (arXiv:2601.03064) for a framework that helps clarify what to do when the uncertainty you care about is parameter uncertainty, predictive uncertainty, or uncertainty in some other derived random variable.
Below, $k$ is the batch size. The design $\mathcal{D}_{1:k}$ represents a set of $k$ candidate experiments (design points, treatments, prompts, etc.), and $y_{1:k}$ is the corresponding batch of outcomes you will observe. Before data collection, they are unknown, but depend on your model’s predictive distribution and $\mathcal{D}_{1:k}$.
When you can run multiple experiments, selecting the single best experiment (repeatedly choosing $k{=}1$) can be suboptimal: you want a batch that is informative together, avoiding internal redundancy and covering the space of uncertainty efficiently.
In principle, you can run this continuously: score designs in real time, collect the next batch, update the model, then re-score after every update.
In practice, computing MI inside a live system is awkward:
- Batch combinatorics: if you have $n$ candidate experiments and you choose batches of size $k$, there are $\binom{n}{k}$ possible batches. Even with greedy or heuristic search, you end up calling the MI estimator many times.
- Posterior refresh + data movement: many estimators assume posterior samples exist (HMC/MCMC). As new data arrives, you also have to pay an inference cost to refresh the model state, ship samples/state to the MI evaluator, score candidate batches, then observe the data and repeat. Realistically, most use a stale model state for scoring, defeating the purpose of automated experiment design.
Best-first adaptive partitioning
Best-first adaptive partitioning is an adaptive quadrature over a discrete (or discretized) outcome space. It performs Bayesian updating inside the MI computation, so candidate batches can be scored without maintaining posterior samples or a separate inference service. The main parameter is a global refinement budget: fix that budget, and per-query compute stays approximately flat for many practical batch sizes.
In integration terms, you can treat it as a single scoring function: given your regression model specification, observed data, and a candidate batch $\mathcal{D}_{1:k}$, it returns an information-gain score for that batch. “Model specification” can be as simple as a likelihood plus the derivatives needed for local updates.
information_gain(model_spec, observed_data, candidate_batch) -> scoreWhere I would use it: repeated MI evaluations inside a design loop, especially batch search, where a fixed per-query latency budget matters and posterior samples are not already sitting around. It is also a reasonable way to try MI-based design before building a full inference service.
Where I would not start with it: settings where you already have high-quality posterior draws on hand, have highly complex models without tractable likelihood evaluations, or are not bottlenecked by latency.
Integration view: before (two-service pipeline) vs after (single scoring call).
observed_data += new_observations
posterior_samples = run_inference(model_spec, observed_data) # e.g., HMC/MCMC
artifact_uri = write_to_storage(posterior_samples) # serialize + publish stateposterior_samples = read_from_storage(artifact_uri)
score = mi_estimate(posterior_samples, candidate_batch) # repeated many times during batch searchobserved_data += new_observations
score = information_gain(model_spec, observed_data, candidate_batch) # repeated many times during batch searchObserved data and a candidate batch go in, an information-gain score comes out. Dependencies can be minimal: standard numerical linear algebra plus your model likelihood.
Results
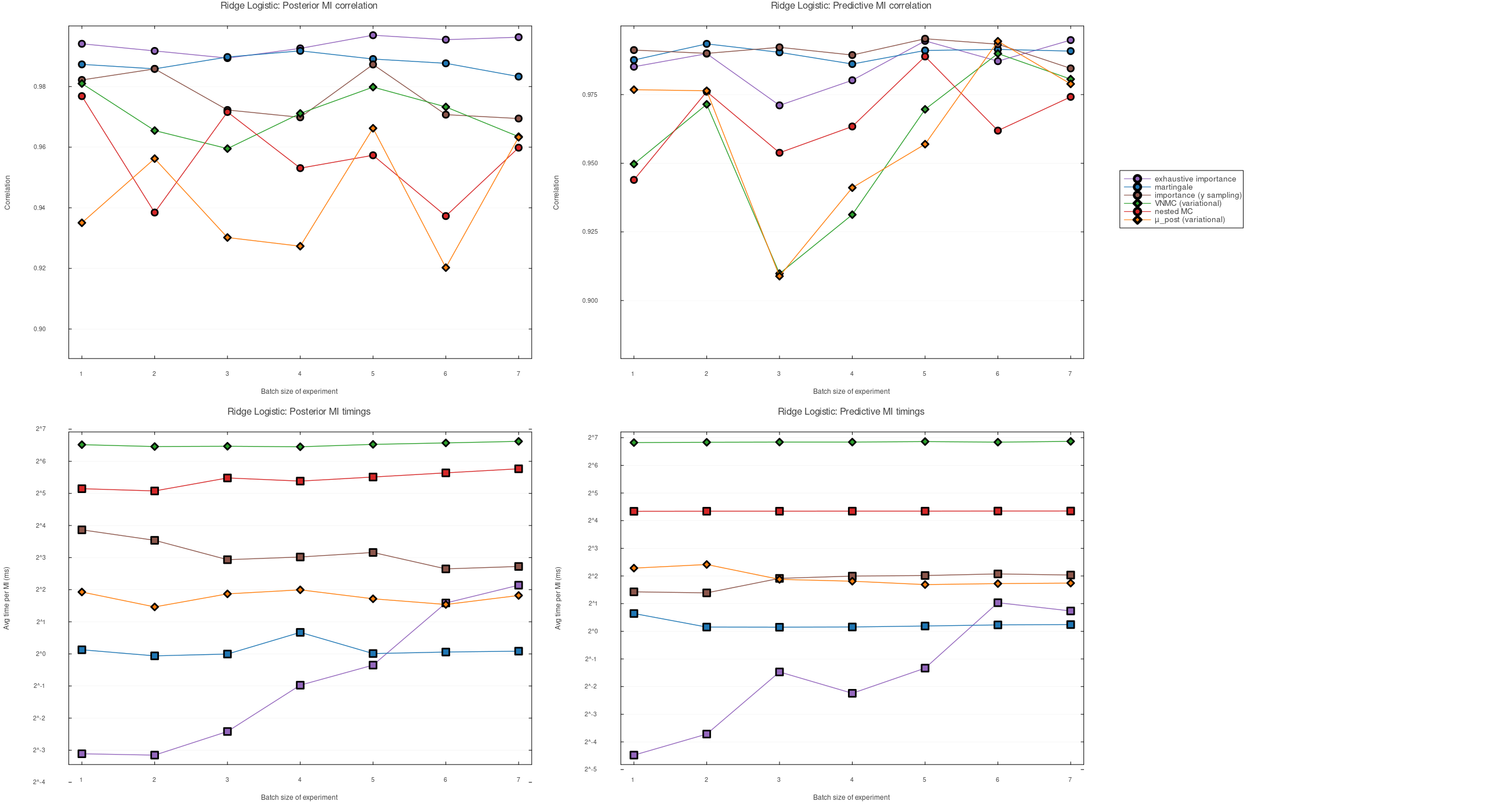
These figures compare multiple estimators of mutual information (MI) used for Bayesian experimental design, across two representative model families (linear regression with unknown observation variance and a nonconjugate ridge-logistic model).
Fidelity is measured by correlation with a high-quality reference MI value for each candidate batch. The reference is kept off the plots, so the figures compare the practical estimators directly.
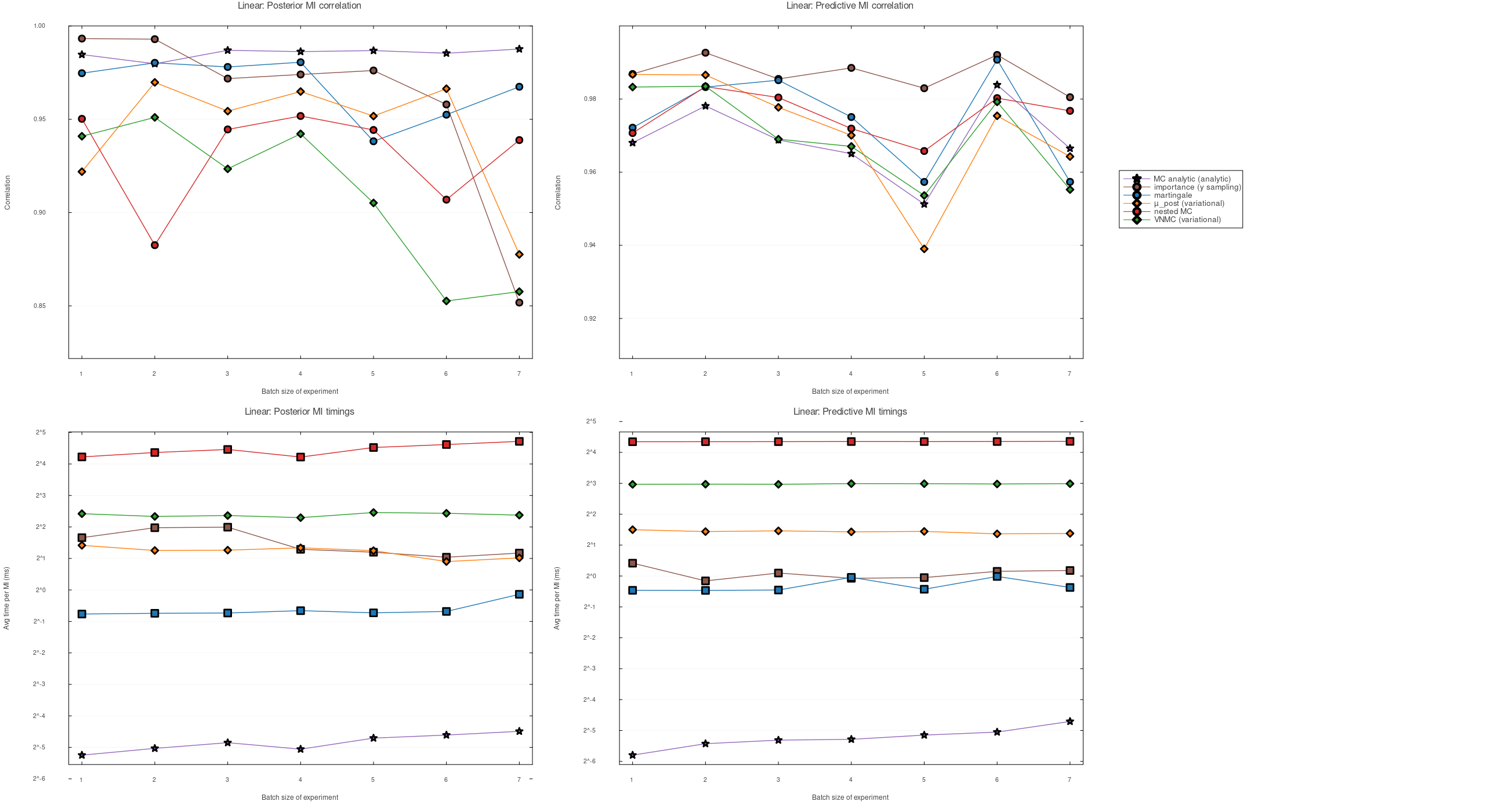
Takeaway: the per-query budget can stay fixed as $k$ grows, while the ranking remains close enough to be useful in these benchmarks.
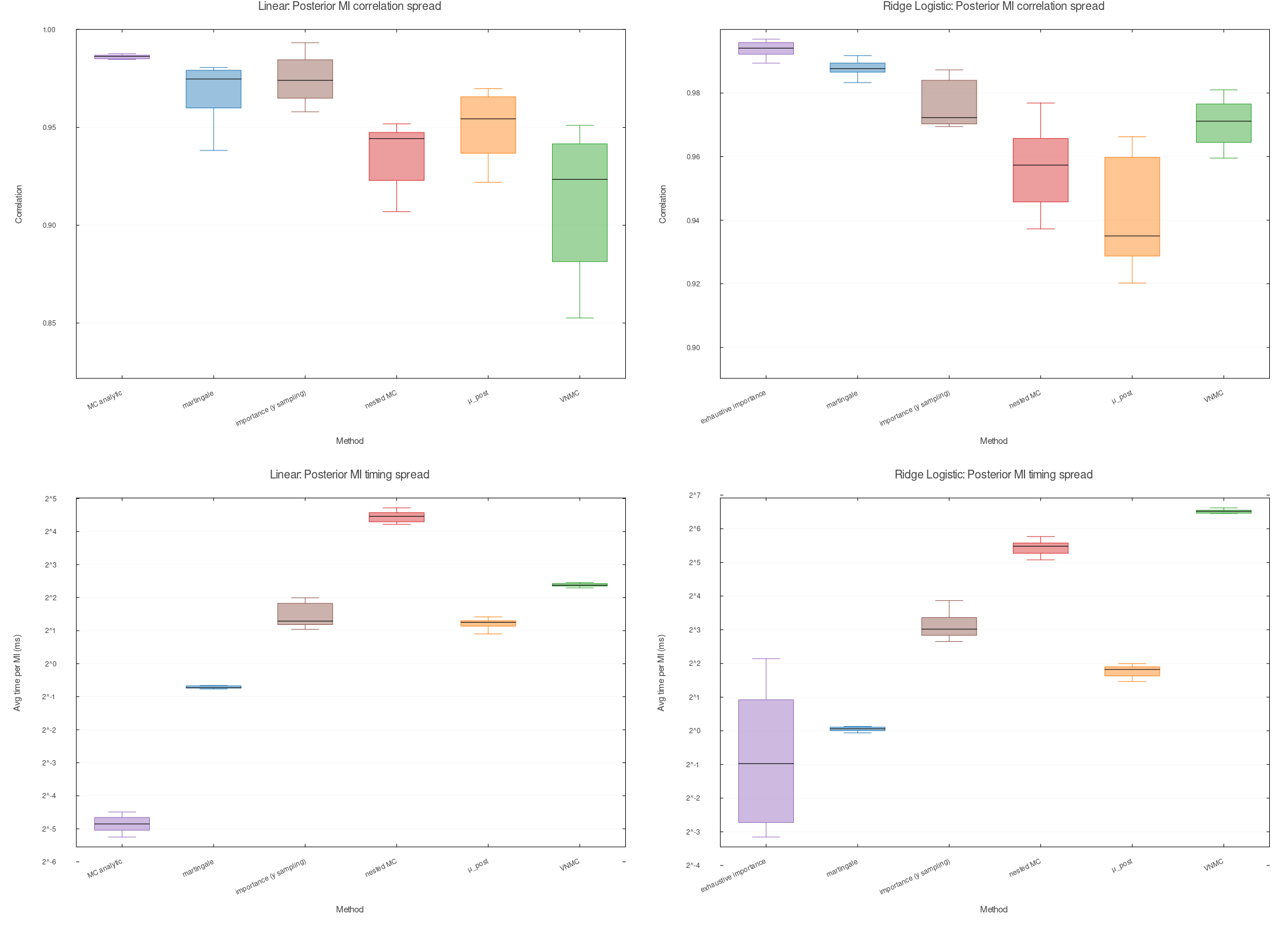
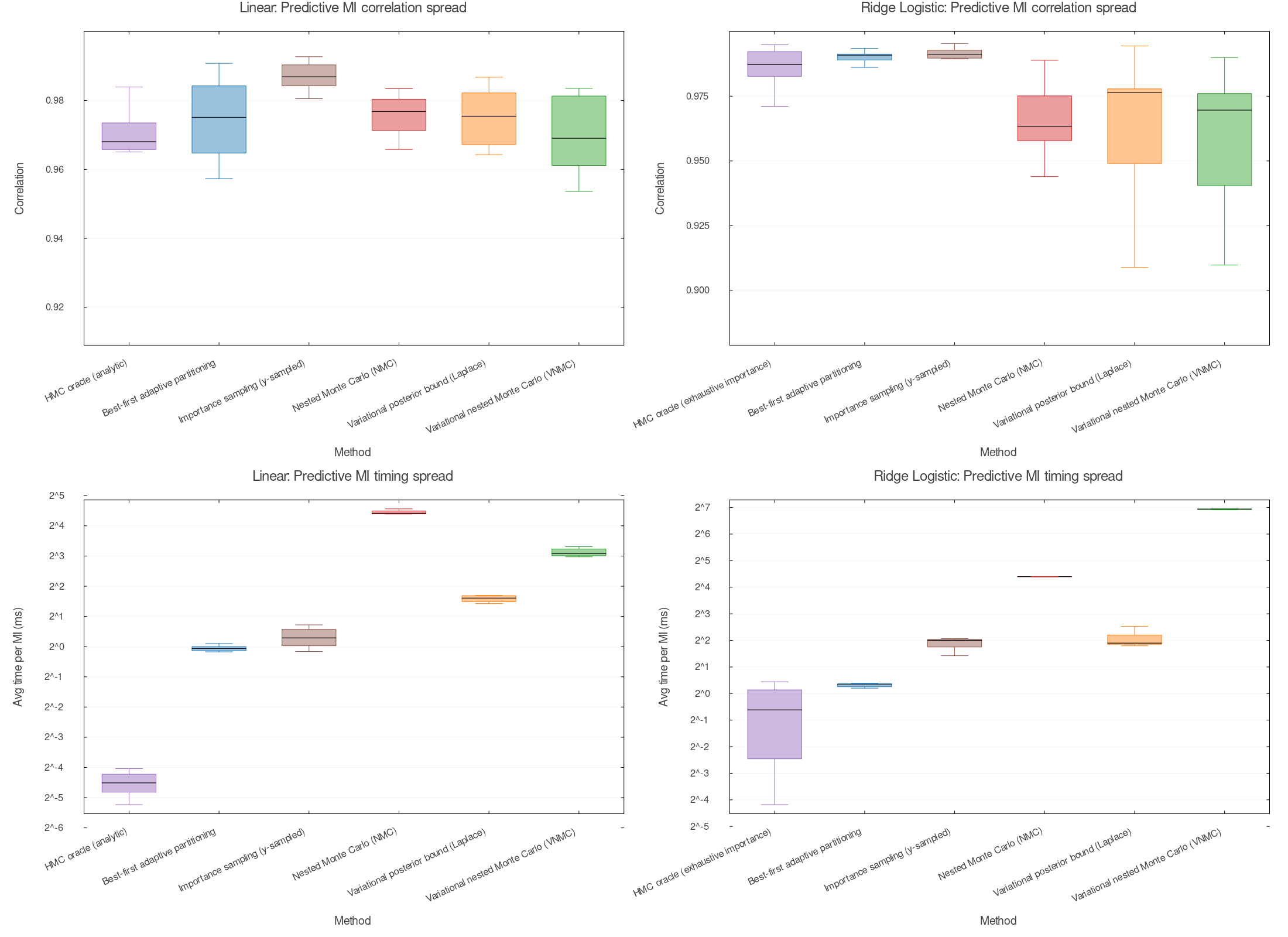
Evaluation
- For each model, we estimate MI for batches of experiments of size $k$, averaged over many randomly chosen design subsets (apples-to-apples across methods at each $k$).
- Fidelity (correlation): Pearson correlation across 20 candidate batches between a method’s MI estimates and the reference MI values (higher means better MI-based ranking).
- Two objectives: posterior MI (learning parameters) and predictive MI (learning predictions at target inputs).
- Timing reports average time per MI evaluation (given whatever cached data the method uses), which is the relevant cost when selecting designs by evaluating MI many times.
Comparison protocol:
- Sampling-based baselines typically require posterior samples (e.g., via HMC/MCMC). That inference can be a large (though one-time) fixed-data cost, and a practical barrier in real workflows. Best-first adaptive partitioning avoids that dependency by updating posterior state as part of MI estimation.
- On these small benchmarks the HMC/MCMC refresh is still a fixed cost outside the plotted MI-query timings. Best-first adaptive partitioning folds the update into the scoring call, so the plotted cost is the full per-query estimator cost.
- To avoid subtle “training on the test set” effects, each sampling-based method uses its own independent posterior draw stream (not shared across methods or with the reference computation).
Key takeaways
- Predictable compute: fixed refinement budgets keep per-query runtime approximately flat as batch size $k$ grows.
- Anytime: early scores can be refined by spending more budget.
- Global refinement: spends compute on high-impact outcome regions.
- No posterior sampling: Bayesian updating happens inside the MI estimator.
- Unified objectives: the same machinery supports posterior and predictive MI.
- Single scorer: raw data + candidate batch in, information-gain score out.
MI Algorithms
Best-first adaptive partitioning
Tree-based adaptive quadrature over a discretized outcome space. It starts with a coarse partition, maintains an approximate posterior state per region, and repeatedly refines the regions with the highest estimated global impact—subject to a strict compute budget. Tunable compute via a global refinement budget; no posterior samples required.
From an integration perspective, it can be exposed as a single scoring function from (model spec, observed data, candidate batch) to information gain. The refinement budget is the knob: you trade runtime for fidelity, and you can keep a strict per-query latency target as $k$ grows.
Nested Monte Carlo (NMC)
General-purpose MI estimator with nested sampling loops. Broadly applicable but can be expensive and variance-limited unless inner sample sizes grow.
Variational nested Monte Carlo (VNMC)
Uses variational approximations to tighten bounds and reduce variance relative to NMC, but remains sample-based and still relies on inference machinery.
Variational posterior bound (Laplace)
Fast approximation via a bound and local posterior geometry; performance depends on how well the approximation matches the true posterior (often weaker in nonconjugate regimes).
Importance sampling (y-sampled)
Reweights prior samples by likelihoods at sampled outcomes. Highly efficient for the logistic regression benchmark, but can have high variance if the likelihoods are small or if the outcome space is large.
Interested?
If you’re selecting experiments with MI, or trying to score designs without maintaining an MCMC pipeline, I’m happy to discuss.